

第20回 日本語でおk
2008年3月 3日
(これまでの増井俊之の「界面潮流」はこちら)
DOS(プロンプト)でもWindowsでもUnixでも英語のコマンドラインが利用されていますし、ほとんどの計算機プログラムやコマンドで“print”のような英単語や英語的な語順が使われています。たとえば、ある値の平方根を計算して表示するプログラムをRubyで書くと
print sqrt(X)
のようになります。Rubyに限らずJavaでもCでも数式や表示の指示に関しては似たような形式が使われることが多いですが、これは
“display the square root of X”
のような英文をそのままの語順で計算機言語に変換した形式になっていますし、“print”や“square”のような英単語がほぼそのままプログラミング言語で利用されていますから、この例では英語表現とプログラム表現はかなり類似しているといえます。
DOSやUnixのコマンドラインでもやはり同様の語順が利用されています。たとえばabc.txtというテキストファイルの中身を並び替えて表示したい場合、Unixではsortというコマンドを使って
% sort abc.txt
のようなコマンドを発行します。この表現も、
“sort (the contents of) abc.txt”
のような英文表記と似た語順と用語が使われていますから、このコマンドは英語的思考にもとづいているといえるでしょう。
一方、このような処理を日本語で表現する場合は
“xの平方根を表示する”
“abc.txtの内容をソートする”
のように全く逆の語順になってしまうわけですが、英語的発想にもとづいたシステム上でプログラムを作成するときはこの順番で考えず、英語の場合と同じように、目的語より先に動詞を持ってくる思考を行なう必要があります。
■連続した処理の表現
単純な計算や処理を行なう場合はこのような素直な英語的発想でプログラムを書けばいいのですが、いくつかの処理が連続する場合は英語的な語順だとうまくいかない場合があります。前述の式をもう少し複雑にして、平方根の逆数を計算して表示したい場合は
print inv(sqrt(x))
のような式を使うのが普通ですが、処理がさらに連続する場合、後で実行する処理ほど前に記述しなければならないという問題が理解を困難にしてしまうことがあります。平方根を計算してからその逆数を計算して表示するという順番なのに、全く逆の順番でプログラムを書かなければならないというのは、英語的かもしれませんが合理的ではありません。
一方、Unixでは処理をする順番にコマンドを右に並べていくことによって連続的な処理を実行させることが可能です。たとえば、あるテキストファイルのコメント行を削除してから並び替えたい場合、ファイルの中身を出力する“cat”コマンド及びパタンにマッチする部分だけを抽出する“grep”コマンドを利用して
% cat abc.txt | grep -v '^#' | sort
のように、処理をひとつずつ“|”で区切って右に並べられるようになっています。この表現法の場合、処理の順番とコマンド並びの順番は完全に一致しているので、実行の順番について混乱することはありません。
Rubyのようなプログラム言語でも、前述のような関数表記を利用するかわりに、処理をピリオド記号で連結する表記を使うことによって、Unixのコマンドラインと同様に、処理を順番に並べたプログラムを書くことができます。たとえば前述のプログラムの場合は
X.sqrt.inv.print
のように表現することが可能です。実行内容は全く同じですが、このように表記する場合は処理の順番とプログラムの並びが一致するので、print inv(sqrt(x))のような表現よりは理解しやすいと思われます。
■日本語によるプログラム表現
このように、処理の順番とプログラム要素の並びはなるべく一致していることが望ましいと思われますが、前述のような式は英語では簡単に表現することができません。あえて順番通りに記述しようとすると
calculate the square root of x, calculate the reciprocal of the result, and print the result
のようになってしまいますが、これはあまり明解な文章とはいえないでしょう。一方、日本語であれば
Xの平方根の逆数を印刷する
という具合に、処理の流れとプログラムの形式と日本語表現を同じ順番で簡潔に記述することができます。このように、実は日本語は計算機処理の記述にかなり適した言語であるということができそうです。
■日本語で本棚演算
第11回の記事で、本棚.orgに投稿されたデータを利用した「本棚演算」というデータマイニング手法について紹介しました。記事中では例として
- 増井の本棚に含まれる本のリストを計算
- その本リストに近い本を持つ本棚のリストを計算
- そのような本棚の中に含まれている本を計算する
のような演算を紹介していますが、これは本棚や本の集合に対する演算を並べたものですから、日本語表記をほとんどそのまま計算機表現に変換することができます。たとえばRubyで表現すると、最初の例は
"増井".bookshelf.books
のような表記を使うことができますし、3行目まで連結したものは
"増井".shelves.books.similarbooks.shelves.books
のようなプログラムで表現できます。
このような性質を利用すると、本棚演算のようなちょっと面倒な計算についても、日本語文を作るのと同じ要領で計算式を作ることができるようになります。下の例では、「増井の本棚に内容が近い本棚に含まれる本のリストを計算する」という作業を日本語で表現することにより、それをダイレクトに計算機プログラムに変換して本棚演算を実行しています。
日本語表現では、計算結果を表現する名詞や計算実行を表現する動詞を自然に文末に配置することができるので、こういった連続処理をうまく連結して、常に日本語として正しい計算式を作ることができます。以下の例では、「増井の本棚」に類似する本棚(似た本を多く含む本棚)に登録されている本を集めて登録の多いものから順に表示するというプログラムを、日本語表現を並べることにことによって作成しています。
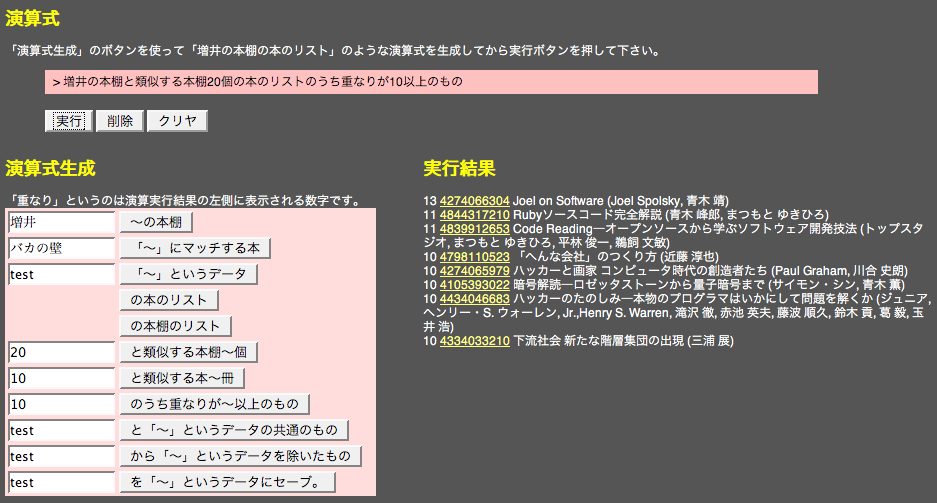
日本語で簡単にプログラムを作れたらいいなぁと思うのは日本人としては自然なことであり、これまで様々な「日本語プログラミング」が提案されてきましたが、広く使われているものはほとんど無いようです。
日本語プログラミングといっても、“print”のようなキーワードを日本語にしただけではあまりメリットが感じられませんが、文の構造と計算機処理の流れを一致させやすいといった日本語特有の性質を充分活用すれば、普通の英語的なプログラミングよりも良い結果が得られる可能性があるでしょう。汎用プログラミング言語として日本語を使うことができなくても、本棚演算のような特定領域での利用には明らかに有用ですから、活用法を検討する価値はありそうです。
![]()
![]()
増井俊之の「界面潮流」
プロフィール
![]()
1959年生まれ。ユーザインタフェース研究。POBox、QuickML、本棚.orgなどのシステムを開発。ソニーコンピュータサイエンス研究所、産業技術総合研究所、Apple Inc.など勤務を経て現在慶應義塾大学教授。著書に『インターフェイスの街角』などがある。
過去の記事
- 第55回 ものづくり革命2011年5月16日
- 第54回 マイIME2011年4月15日
- 第53回 NFC革命2011年3月10日
- 第52回 自己正当化の圧力2011年2月10日
- 第51回 縦書き主義2011年1月17日