

第14回 繰り返しの効用
2007年11月16日
(これまでの増井俊之の「界面潮流」はこちら)
計算機を使うと様々な繰り返し計算を自動化できるはずですが、計算機に繰り返し操作を強要されることもあります。
メールテキストを引用するとき 引用記号を先頭につけるのが 慣習ですが、 手作業で引用記号をつけるのは 面倒なものです。
たとえば上のようなテキストを下のように変換する場合、「行頭に“# ”を挿入して次の行に移動する」という操作を5回繰り返さなければなりません。
# メールテキストを引用するとき # 引用記号を先頭につけるのが # 慣習ですが、 # 手作業で引用記号をつけるのは # 面倒なものです。
5行程度なら良いのですが、百行も千行も同じ操作を繰り返すのは我慢できないでしょう。
■繰り返し操作の検出と自動実行
ユーザが同じ操作を繰り返しているとき、システムがそれを自動的に検出して残りの作業を自動的に実行してくれると便利でしょう。下図はAppleにいたAllen Cypher氏が1990年ごろ開発したEagerというシステムで、ユーザがHyperCard上で同じような処理を繰り返したとき、それを検出して自動実行を助けてくれるというものです。ユーザが同じような操作を繰り返すと、画面に「猫」が出現してユーザの次の操作を予測して表示します。正しく予測してくれているようだと感じられれば、ユーザは猫に頼んで残りの処理を自動実行してもらうことができます。この例では、“1. ”, “2. ”をユーザが入力しているので、猫は次に“3. ”が入力されるだろうという予測を行なっています。
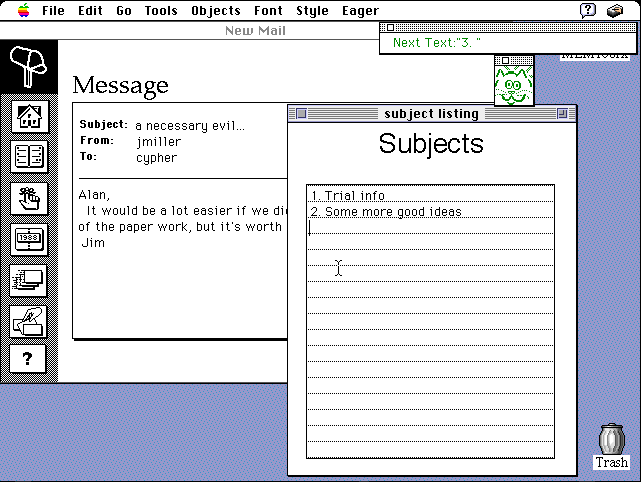
猫は普段は隠れているのですが、繰り返し操作を行なったとき突然猫が出現すると驚いてしまいますし、常に正しい予測を行なってくれるわけではないせいか、Eagerは結局ほとんど流行しませんでした。
一方、高度な予測を行なうのはあきらめて、完全にユーザ主導で単純な繰り返し処理を自動実行させるようにすればうまくいきます。このような方針でDynamic Macroというシステムを作りました。
メールテキストを引用するとき 引用記号を先頭につけるのが 慣習ですが、 手作業で引用記号をつけるのは 面倒なものです。
このテキストに引用符をつけたいとき、まず以下のように最初の2行だけに引用符を付加します。
# メールテキストを引用するとき # 引用記号を先頭につけるのが 慣習ですが、 手作業で引用記号をつけるのは 面倒なものです。
ここでユーザが「繰り返しキー」を押すと、Dynamic Macroはユーザの操作履歴を調べて繰り返しを検出し、「行頭に“# ”を挿入して次の行に移動する」という操作をマクロとして登録して実行します。この結果テキストは以下のようになります。
# メールテキストを引用するとき # 引用記号を先頭につけるのが # 慣習ですが、 手作業で引用記号をつけるのは 面倒なものです。
繰り返しキーを連打すると、キー入力のたびにマクロが実行され、テキストは以下のように変化します。
# メールテキストを引用するとき # 引用記号を先頭につけるのが # 慣習ですが、 # 手作業で引用記号をつけるのは # 面倒なものです。
Dynamic Macroの場合、連打が必要ではありますが、ユーザが驚くことはありませんし、予測を間違う可能性は低いので、かなり実用的に利用することができます。
Cyper氏は最近はIBMでFirefoxの操作を自動化する研究を行なっているようですが、Webの上で様々な繰り返し操作が自動化できると嬉しいことは多そうです。
■繰り返しの予測とデータ圧縮
データが片寄っている場合や、データ中に同じ内容が繰り返し出現する場合は、データを圧縮することが可能です。人間が扱う大抵のデータはこのような性質を持っているので、これをうまく抽出することにより効率的なデータ圧縮ができます。逆に、効率的なデータ圧縮プログラムはデータの片寄りや繰り返しをうまく検出するのが得意だということになります。このようなアルゴリズムを利用すると、ゲームで相手の手を予測できる可能性があります。
効率的なデータ圧縮を行なうアルゴリズムとしてPPM (Prediction by Partial Matching)法というものがあります。PPM法では、データの中の文字列出現頻度を計算することによって次の文字の予測を行ないます。たとえば「abracadab」というデータの次にどの文字が来るか予測する場合、
- 「a」は4回、「b」は2回出現している
- 「b」の後に「r」が続いたことがある
- 「ab」の後に「r」が続いたことがある
- ...
といった情報を累積して確率を推定します。この場合、 (3)から考えると次の文字は「r」である確率が高いと思われますが、(1)も考慮すると「a」の確率もある、という風に計算を行ないます。
この原理を使ってじゃんけんゲームを作ってみました。長く勝負すると必ず負けてしまうので、確かに効果的な予測が行なわれていることがわかります。
人間の行動や人間が目にするものは繰り返しで満ちています。毎日同じような行動をしていると、今日の行動記録は「昨日と同じ」のように圧縮可能になってしまうので、歳をとるとだんだん時間がたつのが速く感じられてしまうのでしょう。繰り返しの少ない/圧縮しにくい人生を送るために、無駄な繰り返しを自動化するツールを活用しましょう。
![]()
![]()
増井俊之の「界面潮流」
プロフィール
![]()
1959年生まれ。ユーザインタフェース研究。POBox、QuickML、本棚.orgなどのシステムを開発。ソニーコンピュータサイエンス研究所、産業技術総合研究所、Apple Inc.など勤務を経て現在慶應義塾大学教授。著書に『インターフェイスの街角』などがある。
過去の記事
- 第55回 ものづくり革命2011年5月16日
- 第54回 マイIME2011年4月15日
- 第53回 NFC革命2011年3月10日
- 第52回 自己正当化の圧力2011年2月10日
- 第51回 縦書き主義2011年1月17日